Database
Scarica zip esercizi
In questo tutorial affronteremo il tema database in Python:
Uso SQLStudio con connessione a SQLite
semplici query SQL da Python
esempi con libreria Pandas
Che fare
scompatta lo zip in una cartella, dovresti ottenere qualcosa del genere:
database
database.ipynb
database-sol.ipynb
jupman.py
ATTENZIONE: Per essere visualizzato correttamente, il file del notebook DEVE essere nella cartella szippata.
apri il Jupyter Notebook da quella cartella. Due cose dovrebbero aprirsi, prima una console e poi un browser. Il browser dovrebbe mostrare una lista di file: naviga la lista e apri il notebook
database.ipynbProsegui leggendo il file degli esercizi, ogni tanto al suo interno troverai delle scritte ESERCIZIO, che ti chiederanno di scrivere dei comandi Python nelle celle successive.
Scorciatoie da tastiera:
Per eseguire il codice Python dentro una cella di Jupyter, premi
Control+InvioPer eseguire il codice Python dentro una cella di Jupyter E selezionare la cella seguente, premi
Shift+InvioPer eseguire il codice Python dentro una cella di Jupyter E creare una nuova cella subito dopo, premi
Alt+InvioSe per caso il Notebook sembra inchiodato, prova a selezionare
Kernel -> Restart
Guardiamo il database
Proveremo ad accedere via SQLiteStudio e Python al database Chinhook.
Il modello dati di Chinook rappresenta uno store online di canzoni, e include tabelle per artisti (Artist), album (Album), tracce (Track), fatture (Invoice) e clienti (Customer):

I dati provengono da varie sorgenti:
I dati relativi alle canzoni sono stati creati usando dati reali dalla libreria iTunes
Le informazioni sui clienti sono state create manualmente usando nomi fittizi
Gli indirizzi sono georeferenziabili su Google Maps, e altri dati ben formattatati (telefono, fax, email, etc.)
Le informazioni sulle vendite sono auto-generate usando dati casuali per lungo un periodo di 4 anni
Connessione in SQLStudio
Scarica e prova a lanciare SQLite Studio (non serve nemmeno l’installazione). Se ti dà problemi, in alternativa prova SQLite browser:
Una volta scaricato e szippato SQLStudio, eseguilo e poi:
Dal menu in alto, clicca
Database->Add Databasee connettilo al databasechinook.sqlite:

Clicca su
Test connectionper verificare che la connessione funzioni, poi premiOK.
Cominciamo a guardare una tabella semplice come Album.
ESERCIZIO: Prima di procedere, in SQLiteStudio, nel menu a sinistra sotto il nodo Tables fai doppio click sulla tabella Album.
Adesso nel pannello principale a destra seleziona la tab Data:

Vediamo che ci sono 3 colonne, due con numeri AlbumId e ArtistId e una di stringhe, chiamata Title
NOTA: I nomi delle colonne in SQL possono essere arbitrariamente scelte da chi crea i database. Quindi non è strettamente necessario che i nomi delle colonne numeriche terminino con Id.
Connessione in Python
Proviamo adesso a recuperare gli stessi dati della tabella Album in Python. SQLite è talmente popolare che la libreria per accederlo viene fornita direttamente con Python, quindi non ci servirà installare niente di particolare e possiamo tuffarci subito nel codice:
[1]:
import sqlite3
conn = sqlite3.connect('file:chinook.sqlite?mode=rw', uri=True)
L’operazione qua sopra crea un oggetto connessione e lo assegna alla variabile conn. A cosa ci connettiamo? Ad un database indicato dalla uri file:chinook.sqlite?mode=rw. Ma cos’è una URI? E’ una stringa che denota una locazione da qualche parte, potrebbe essere un database accessibile come servizio via internet, o un file sul nostro disco: nel nostro caso vogliamo indicare un database che abbiamo su disco, perciò useremo il protocollo file:
SQLite andrà quindi a cercarsi su disco il file chinook.sqlite, nella stessa cartella dove stiamo eseguendo Jupyter. Se il file fosse in qualche sottodirectory, potremmo scrivere per es. qualche/cartella/chinook.sqlite
NOTA 1: ci stiamo connettendo al database in formato binario .sqlite , NON al file di testo .sql !
NOTA 2: stiamo specificando che lo vogliamo aprire in modalità mode=rw, cioè di lettura + scrittura (Read Write). SE il database non esiste, questa funzione lancerà un errore.
NOTA 3: se volessimo creare un nuovo database, dovremmo usare la modalità lettura + scrittura + creazione (Read Write Creation), specificando come parametro mode=rwc (notare la c in più)
NOTA 4: in tanti sistemi di database (SQLite incluso), di default quando ci si connette ad un database su disco non esistente, ne creano uno. Questo è causa di tantissime imprecazioni, perchè se si sbaglia a scrivere il nome del database non saranno segnalati errori e ci si ritroverà connessi ad un database vuoto, chiedendosi che fine abbiano fatto i dati. E ci si troverà anche il disco pieno di file di database con nomi sbagliati!
Tramite l’oggetto connessione conn possiamo creare un cosiddetto cursore, che ci consentirà di eseguire query verso il database. Usare una connessione per fare query equivale a chiedere una risorsa del sistema a Python. Le regole di buona educazione ci dicono che quando chiediamo in prestito qualcosa, dopo averlo usato lo si restituisce. La ‘restituzione’ equivarrebbe in Python a chiudere la risorsa aperta. Ma mentre usiamo la risorsa si potrebbe verificare un errore, che potrebbe
impedirci di chiudere la risorsa correttamente. Per indicare a Pyhton che vogliamo che la risorsa venga chiusa automaticamente in caso di errore, usiamo il comando with come abbiamo fatto per i file:
[2]:
import sqlite3
conn = sqlite3.connect('file:chinook.sqlite?mode=rw', uri=True)
with conn: # col blocco with ci cauteliamo da errori imprevisti
cursore = conn.cursor() # otteniamo il cursore
cursore.execute("SELECT * FROM Album LIMIT 5") # eseguiamo una query in
# linguaggio SQL al database
# notare che execute di per
# sè non ritorna
for riga in cursore.fetchall(): # cursore fetchall() genera una sequenza
# di righe di risultato della query.
print(riga) # una alla volta, le righe vengono
# assegnate all'oggetto `riga`
(1, 'For Those About To Rock We Salute You', 1)
(2, 'Balls to the Wall', 2)
(3, 'Restless and Wild', 2)
(4, 'Let There Be Rock', 1)
(5, 'Big Ones', 3)
Finalmente abbiamo ottenuto la lista delle prime 5 righe dal database per la tabella Album.
ESERCIZIO: prova a scrivere qua sotto le istruzioni per stampare direttamente tutto risultato di cursore.fetchall() .
Qual’è il tipo di oggetto che ottieni?
Inoltre, qual’è il tipo delle singole righe (nota che sono rappresentate in parentesi tonde)?
[3]:
# scrivi qui il codice
Performance
I database sono pensati apposta per gestire grandi quantità dati che risiedono su hard-disk. Vediamo brevemente i vari tipi di memoria disponibili nel computer, e come vengono usati dai database:
Memoria |
Velocità* |
Quantità |
Note |
|---|---|---|---|
RAM |
1x |
4-16 gigabyte |
si cancella allo spegnimento del computer |
Disco SSD |
2x-10x |
centinaia di gigabyte |
persistente, ma troppe scritture la rovinano |
hard disk |
100x |
centinaia di gigabyte, terabyte |
persistente, può sopportare numerose scritture |
* in lentezza rispetto a RAM
Se facciamo delle query complesse che potenzialmente vanno a elaborare parecchi dati, non sempre questi possono stare tutti in RAM. Pensiamo come esempio di chiedere al db di calcolare la media delle vendite di tutte le canzoni (supponi di avere terabyte di canzoni). Fortunatamente, spesso il database si arrangia da solo a creare un piano per ottimizzare l’uso delle risorse. Nel caso della media delle canzoni vendute, potrebbe per esempio eseguire autonomamente tutte queste operazioni:
caricare dall’hard-disk alla RAM 4 gigabyte di canzoni
calcolare media vendite di queste canzoni sul blocco corrente in RAM
scaricare la RAM
caricare dall’hard-disk alla RAM altri 4 gigabyte di canzoni
calcolare media vendite del secondo blocco canzoni in RAM, e fare media con la media risultata dal primo blocco
scaricare la RAM
etc ….
Nello scenario ideale possiamo scrivere query SQL complesse e sperare che il database se la cavi rapidamente a darci direttamente i risultati che ci servono in Python, salvandoci parecchio di lavoro. Purtroppo a volte ciò non è possibile, ci accorgiamo che il database ci mette una vita e bisogna ottimizzare a mano la query SQL, oppure il modo in cui carichiamo e rielaboriamo i dati in Python. Per ragioni di spazio in questo tutorial tratteremo solo l’ultimo caso, in modo molto semplice.
Prendere i dati un po’ alla volta
Nei primi comandi Python sopra abbiamo visto come prelevare un po’ di righe dal DB usando l’opzione SQL LIMIT, e come caricare tutte queste righe in un colpo solo in una lista Python con fetchall. E se volessimo stampare a video tutte le righe di una tabella da 1 terabyte, come faremmo? Sicuramente, se provassimo a caricarle tutte in una lista, Python finirebbe con saturare la memoria RAM. In alternativa al fetchall, possiamo usare il comando fetchmany, che prende un po’ di
righe alla volta:
[4]:
import sqlite3
conn = sqlite3.connect('file:chinook.sqlite?mode=rw', uri=True)
with conn:
cursore = conn.cursor()
cursore.execute("SELECT * FROM Album")
while True: # fintanto che True è vero,
# cioè il ciclo apparentemente non termina mai ...
righe = cursore.fetchmany(5) # prende 5 righe
if len(righe) > 0: # se abbiamo delle righe, le stampa
for riga in righe:
print(riga)
else: # altrimenti interrompe
break # forzatamente il ciclo while
(1, 'For Those About To Rock We Salute You', 1)
(2, 'Balls to the Wall', 2)
(3, 'Restless and Wild', 2)
(4, 'Let There Be Rock', 1)
(5, 'Big Ones', 3)
(6, 'Jagged Little Pill', 4)
(7, 'Facelift', 5)
(8, 'Warner 25 Anos', 6)
(9, 'Plays Metallica By Four Cellos', 7)
(10, 'Audioslave', 8)
(11, 'Out Of Exile', 8)
(12, 'BackBeat Soundtrack', 9)
(13, 'The Best Of Billy Cobham', 10)
(14, 'Alcohol Fueled Brewtality Live! [Disc 1]', 11)
(15, 'Alcohol Fueled Brewtality Live! [Disc 2]', 11)
(16, 'Black Sabbath', 12)
(17, 'Black Sabbath Vol. 4 (Remaster)', 12)
(18, 'Body Count', 13)
(19, 'Chemical Wedding', 14)
(20, 'The Best Of Buddy Guy - The Millenium Collection', 15)
(21, 'Prenda Minha', 16)
(22, 'Sozinho Remix Ao Vivo', 16)
(23, 'Minha Historia', 17)
(24, 'Afrociberdelia', 18)
(25, 'Da Lama Ao Caos', 18)
(26, 'Acústico MTV [Live]', 19)
(27, 'Cidade Negra - Hits', 19)
(28, 'Na Pista', 20)
(29, 'Axé Bahia 2001', 21)
(30, 'BBC Sessions [Disc 1] [Live]', 22)
(31, 'Bongo Fury', 23)
(32, 'Carnaval 2001', 21)
(33, 'Chill: Brazil (Disc 1)', 24)
(34, 'Chill: Brazil (Disc 2)', 6)
(35, 'Garage Inc. (Disc 1)', 50)
(36, 'Greatest Hits II', 51)
(37, 'Greatest Kiss', 52)
(38, 'Heart of the Night', 53)
(39, 'International Superhits', 54)
(40, 'Into The Light', 55)
(41, 'Meus Momentos', 56)
(42, 'Minha História', 57)
(43, 'MK III The Final Concerts [Disc 1]', 58)
(44, 'Physical Graffiti [Disc 1]', 22)
(45, 'Sambas De Enredo 2001', 21)
(46, 'Supernatural', 59)
(47, 'The Best of Ed Motta', 37)
(48, 'The Essential Miles Davis [Disc 1]', 68)
(49, 'The Essential Miles Davis [Disc 2]', 68)
(50, 'The Final Concerts (Disc 2)', 58)
(51, "Up An' Atom", 69)
(52, 'Vinícius De Moraes - Sem Limite', 70)
(53, 'Vozes do MPB', 21)
(54, 'Chronicle, Vol. 1', 76)
(55, 'Chronicle, Vol. 2', 76)
(56, 'Cássia Eller - Coleção Sem Limite [Disc 2]', 77)
(57, 'Cássia Eller - Sem Limite [Disc 1]', 77)
(58, 'Come Taste The Band', 58)
(59, 'Deep Purple In Rock', 58)
(60, 'Fireball', 58)
(61, "Knocking at Your Back Door: The Best Of Deep Purple in the 80's", 58)
(62, 'Machine Head', 58)
(63, 'Purpendicular', 58)
(64, 'Slaves And Masters', 58)
(65, 'Stormbringer', 58)
(66, 'The Battle Rages On', 58)
(67, "Vault: Def Leppard's Greatest Hits", 78)
(68, 'Outbreak', 79)
(69, 'Djavan Ao Vivo - Vol. 02', 80)
(70, 'Djavan Ao Vivo - Vol. 1', 80)
(71, 'Elis Regina-Minha História', 41)
(72, 'The Cream Of Clapton', 81)
(73, 'Unplugged', 81)
(74, 'Album Of The Year', 82)
(75, 'Angel Dust', 82)
(76, 'King For A Day Fool For A Lifetime', 82)
(77, 'The Real Thing', 82)
(78, 'Deixa Entrar', 83)
(79, 'In Your Honor [Disc 1]', 84)
(80, 'In Your Honor [Disc 2]', 84)
(81, 'One By One', 84)
(82, 'The Colour And The Shape', 84)
(83, 'My Way: The Best Of Frank Sinatra [Disc 1]', 85)
(84, 'Roda De Funk', 86)
(85, 'As Canções de Eu Tu Eles', 27)
(86, 'Quanta Gente Veio Ver (Live)', 27)
(87, 'Quanta Gente Veio ver--Bônus De Carnaval', 27)
(88, 'Faceless', 87)
(89, 'American Idiot', 54)
(90, 'Appetite for Destruction', 88)
(91, 'Use Your Illusion I', 88)
(92, 'Use Your Illusion II', 88)
(93, 'Blue Moods', 89)
(94, 'A Matter of Life and Death', 90)
(95, 'A Real Dead One', 90)
(96, 'A Real Live One', 90)
(97, 'Brave New World', 90)
(98, 'Dance Of Death', 90)
(99, 'Fear Of The Dark', 90)
(100, 'Iron Maiden', 90)
(101, 'Killers', 90)
(102, 'Live After Death', 90)
(103, 'Live At Donington 1992 (Disc 1)', 90)
(104, 'Live At Donington 1992 (Disc 2)', 90)
(105, 'No Prayer For The Dying', 90)
(106, 'Piece Of Mind', 90)
(107, 'Powerslave', 90)
(108, 'Rock In Rio [CD1]', 90)
(109, 'Rock In Rio [CD2]', 90)
(110, 'Seventh Son of a Seventh Son', 90)
(111, 'Somewhere in Time', 90)
(112, 'The Number of The Beast', 90)
(113, 'The X Factor', 90)
(114, 'Virtual XI', 90)
(115, 'Sex Machine', 91)
(116, 'Emergency On Planet Earth', 92)
(117, 'Synkronized', 92)
(118, 'The Return Of The Space Cowboy', 92)
(119, 'Get Born', 93)
(120, 'Are You Experienced?', 94)
(121, 'Surfing with the Alien (Remastered)', 95)
(122, 'Jorge Ben Jor 25 Anos', 46)
(123, 'Jota Quest-1995', 96)
(124, 'Cafezinho', 97)
(125, 'Living After Midnight', 98)
(126, 'Unplugged [Live]', 52)
(127, 'BBC Sessions [Disc 2] [Live]', 22)
(128, 'Coda', 22)
(129, 'Houses Of The Holy', 22)
(130, 'In Through The Out Door', 22)
(131, 'IV', 22)
(132, 'Led Zeppelin I', 22)
(133, 'Led Zeppelin II', 22)
(134, 'Led Zeppelin III', 22)
(135, 'Physical Graffiti [Disc 2]', 22)
(136, 'Presence', 22)
(137, 'The Song Remains The Same (Disc 1)', 22)
(138, 'The Song Remains The Same (Disc 2)', 22)
(139, 'A TempestadeTempestade Ou O Livro Dos Dias', 99)
(140, 'Mais Do Mesmo', 99)
(141, 'Greatest Hits', 100)
(142, 'Lulu Santos - RCA 100 Anos De Música - Álbum 01', 101)
(143, 'Lulu Santos - RCA 100 Anos De Música - Álbum 02', 101)
(144, 'Misplaced Childhood', 102)
(145, 'Barulhinho Bom', 103)
(146, 'Seek And Shall Find: More Of The Best (1963-1981)', 104)
(147, 'The Best Of Men At Work', 105)
(148, 'Black Album', 50)
(149, 'Garage Inc. (Disc 2)', 50)
(150, "Kill 'Em All", 50)
(151, 'Load', 50)
(152, 'Master Of Puppets', 50)
(153, 'ReLoad', 50)
(154, 'Ride The Lightning', 50)
(155, 'St. Anger', 50)
(156, '...And Justice For All', 50)
(157, 'Miles Ahead', 68)
(158, 'Milton Nascimento Ao Vivo', 42)
(159, 'Minas', 42)
(160, 'Ace Of Spades', 106)
(161, 'Demorou...', 108)
(162, 'Motley Crue Greatest Hits', 109)
(163, 'From The Muddy Banks Of The Wishkah [Live]', 110)
(164, 'Nevermind', 110)
(165, 'Compositores', 111)
(166, 'Olodum', 112)
(167, 'Acústico MTV', 113)
(168, 'Arquivo II', 113)
(169, 'Arquivo Os Paralamas Do Sucesso', 113)
(170, 'Bark at the Moon (Remastered)', 114)
(171, 'Blizzard of Ozz', 114)
(172, 'Diary of a Madman (Remastered)', 114)
(173, 'No More Tears (Remastered)', 114)
(174, 'Tribute', 114)
(175, 'Walking Into Clarksdale', 115)
(176, 'Original Soundtracks 1', 116)
(177, 'The Beast Live', 117)
(178, 'Live On Two Legs [Live]', 118)
(179, 'Pearl Jam', 118)
(180, 'Riot Act', 118)
(181, 'Ten', 118)
(182, 'Vs.', 118)
(183, 'Dark Side Of The Moon', 120)
(184, 'Os Cães Ladram Mas A Caravana Não Pára', 121)
(185, 'Greatest Hits I', 51)
(186, 'News Of The World', 51)
(187, 'Out Of Time', 122)
(188, 'Green', 124)
(189, 'New Adventures In Hi-Fi', 124)
(190, 'The Best Of R.E.M.: The IRS Years', 124)
(191, 'Cesta Básica', 125)
(192, 'Raul Seixas', 126)
(193, 'Blood Sugar Sex Magik', 127)
(194, 'By The Way', 127)
(195, 'Californication', 127)
(196, 'Retrospective I (1974-1980)', 128)
(197, 'Santana - As Years Go By', 59)
(198, 'Santana Live', 59)
(199, 'Maquinarama', 130)
(200, 'O Samba Poconé', 130)
(201, 'Judas 0: B-Sides and Rarities', 131)
(202, 'Rotten Apples: Greatest Hits', 131)
(203, 'A-Sides', 132)
(204, 'Morning Dance', 53)
(205, 'In Step', 133)
(206, 'Core', 134)
(207, 'Mezmerize', 135)
(208, '[1997] Black Light Syndrome', 136)
(209, 'Live [Disc 1]', 137)
(210, 'Live [Disc 2]', 137)
(211, 'The Singles', 138)
(212, 'Beyond Good And Evil', 139)
(213, 'Pure Cult: The Best Of The Cult (For Rockers, Ravers, Lovers & Sinners) [UK]', 139)
(214, 'The Doors', 140)
(215, 'The Police Greatest Hits', 141)
(216, 'Hot Rocks, 1964-1971 (Disc 1)', 142)
(217, 'No Security', 142)
(218, 'Voodoo Lounge', 142)
(219, 'Tangents', 143)
(220, 'Transmission', 143)
(221, 'My Generation - The Very Best Of The Who', 144)
(222, 'Serie Sem Limite (Disc 1)', 145)
(223, 'Serie Sem Limite (Disc 2)', 145)
(224, 'Acústico', 146)
(225, 'Volume Dois', 146)
(226, 'Battlestar Galactica: The Story So Far', 147)
(227, 'Battlestar Galactica, Season 3', 147)
(228, 'Heroes, Season 1', 148)
(229, 'Lost, Season 3', 149)
(230, 'Lost, Season 1', 149)
(231, 'Lost, Season 2', 149)
(232, 'Achtung Baby', 150)
(233, "All That You Can't Leave Behind", 150)
(234, 'B-Sides 1980-1990', 150)
(235, 'How To Dismantle An Atomic Bomb', 150)
(236, 'Pop', 150)
(237, 'Rattle And Hum', 150)
(238, 'The Best Of 1980-1990', 150)
(239, 'War', 150)
(240, 'Zooropa', 150)
(241, 'UB40 The Best Of - Volume Two [UK]', 151)
(242, 'Diver Down', 152)
(243, 'The Best Of Van Halen, Vol. I', 152)
(244, 'Van Halen', 152)
(245, 'Van Halen III', 152)
(246, 'Contraband', 153)
(247, 'Vinicius De Moraes', 72)
(248, 'Ao Vivo [IMPORT]', 155)
(249, 'The Office, Season 1', 156)
(250, 'The Office, Season 2', 156)
(251, 'The Office, Season 3', 156)
(252, 'Un-Led-Ed', 157)
(253, 'Battlestar Galactica (Classic), Season 1', 158)
(254, 'Aquaman', 159)
(255, 'Instant Karma: The Amnesty International Campaign to Save Darfur', 150)
(256, 'Speak of the Devil', 114)
(257, '20th Century Masters - The Millennium Collection: The Best of Scorpions', 179)
(258, 'House of Pain', 180)
(259, 'Radio Brasil (O Som da Jovem Vanguarda) - Seleccao de Henrique Amaro', 36)
(260, 'Cake: B-Sides and Rarities', 196)
(261, 'LOST, Season 4', 149)
(262, 'Quiet Songs', 197)
(263, 'Muso Ko', 198)
(264, 'Realize', 199)
(265, 'Every Kind of Light', 200)
(266, 'Duos II', 201)
(267, 'Worlds', 202)
(268, 'The Best of Beethoven', 203)
(269, 'Temple of the Dog', 204)
(270, 'Carry On', 205)
(271, 'Revelations', 8)
(272, 'Adorate Deum: Gregorian Chant from the Proper of the Mass', 206)
(273, 'Allegri: Miserere', 207)
(274, 'Pachelbel: Canon & Gigue', 208)
(275, 'Vivaldi: The Four Seasons', 209)
(276, 'Bach: Violin Concertos', 210)
(277, 'Bach: Goldberg Variations', 211)
(278, 'Bach: The Cello Suites', 212)
(279, 'Handel: The Messiah (Highlights)', 213)
(280, 'The World of Classical Favourites', 214)
(281, 'Sir Neville Marriner: A Celebration', 215)
(282, 'Mozart: Wind Concertos', 216)
(283, 'Haydn: Symphonies 99 - 104', 217)
(284, 'Beethoven: Symhonies Nos. 5 & 6', 218)
(285, 'A Soprano Inspired', 219)
(286, 'Great Opera Choruses', 220)
(287, 'Wagner: Favourite Overtures', 221)
(288, 'Fauré: Requiem, Ravel: Pavane & Others', 222)
(289, 'Tchaikovsky: The Nutcracker', 223)
(290, 'The Last Night of the Proms', 224)
(291, 'Puccini: Madama Butterfly - Highlights', 225)
(292, 'Holst: The Planets, Op. 32 & Vaughan Williams: Fantasies', 226)
(293, "Pavarotti's Opera Made Easy", 227)
(294, "Great Performances - Barber's Adagio and Other Romantic Favorites for Strings", 228)
(295, 'Carmina Burana', 229)
(296, 'A Copland Celebration, Vol. I', 230)
(297, 'Bach: Toccata & Fugue in D Minor', 231)
(298, 'Prokofiev: Symphony No.1', 232)
(299, 'Scheherazade', 233)
(300, 'Bach: The Brandenburg Concertos', 234)
(301, 'Chopin: Piano Concertos Nos. 1 & 2', 235)
(302, 'Mascagni: Cavalleria Rusticana', 236)
(303, 'Sibelius: Finlandia', 237)
(304, 'Beethoven Piano Sonatas: Moonlight & Pastorale', 238)
(305, 'Great Recordings of the Century - Mahler: Das Lied von der Erde', 240)
(306, 'Elgar: Cello Concerto & Vaughan Williams: Fantasias', 241)
(307, 'Adams, John: The Chairman Dances', 242)
(308, "Tchaikovsky: 1812 Festival Overture, Op.49, Capriccio Italien & Beethoven: Wellington's Victory", 243)
(309, 'Palestrina: Missa Papae Marcelli & Allegri: Miserere', 244)
(310, 'Prokofiev: Romeo & Juliet', 245)
(311, 'Strauss: Waltzes', 226)
(312, 'Berlioz: Symphonie Fantastique', 245)
(313, 'Bizet: Carmen Highlights', 246)
(314, 'English Renaissance', 247)
(315, 'Handel: Music for the Royal Fireworks (Original Version 1749)', 208)
(316, 'Grieg: Peer Gynt Suites & Sibelius: Pelléas et Mélisande', 248)
(317, 'Mozart Gala: Famous Arias', 249)
(318, 'SCRIABIN: Vers la flamme', 250)
(319, 'Armada: Music from the Courts of England and Spain', 251)
(320, 'Mozart: Symphonies Nos. 40 & 41', 248)
(321, 'Back to Black', 252)
(322, 'Frank', 252)
(323, 'Carried to Dust (Bonus Track Version)', 253)
(324, "Beethoven: Symphony No. 6 'Pastoral' Etc.", 254)
(325, 'Bartok: Violin & Viola Concertos', 255)
(326, "Mendelssohn: A Midsummer Night's Dream", 256)
(327, 'Bach: Orchestral Suites Nos. 1 - 4', 257)
(328, 'Charpentier: Divertissements, Airs & Concerts', 258)
(329, 'South American Getaway', 259)
(330, 'Górecki: Symphony No. 3', 260)
(331, 'Purcell: The Fairy Queen', 261)
(332, 'The Ultimate Relexation Album', 262)
(333, 'Purcell: Music for the Queen Mary', 263)
(334, 'Weill: The Seven Deadly Sins', 264)
(335, 'J.S. Bach: Chaconne, Suite in E Minor, Partita in E Major & Prelude, Fugue and Allegro', 265)
(336, 'Prokofiev: Symphony No.5 & Stravinksy: Le Sacre Du Printemps', 248)
(337, 'Szymanowski: Piano Works, Vol. 1', 266)
(338, 'Nielsen: The Six Symphonies', 267)
(339, "Great Recordings of the Century: Paganini's 24 Caprices", 268)
(340, "Liszt - 12 Études D'Execution Transcendante", 269)
(341, 'Great Recordings of the Century - Shubert: Schwanengesang, 4 Lieder', 270)
(342, 'Locatelli: Concertos for Violin, Strings and Continuo, Vol. 3', 271)
(343, 'Respighi:Pines of Rome', 226)
(344, "Schubert: The Late String Quartets & String Quintet (3 CD's)", 272)
(345, "Monteverdi: L'Orfeo", 273)
(346, 'Mozart: Chamber Music', 274)
(347, 'Koyaanisqatsi (Soundtrack from the Motion Picture)', 275)
Passare parametri alla query
E se volessimo passare agevolmente dei parametri alla query, come per esempio il numero dei risultati da ottenere? Per fare ciò possiamo usare dei cosiddetti placeholder, cioè dei caratteri punto di domanda ? che segnano dove vorremmo mettere le variabili. In questo caso sistituiremo il 5 con un punto di domanda, e passeremo il 5 in una lista di parametri a parte:
[5]:
import sqlite3
conn = sqlite3.connect('file:chinook.sqlite?mode=rw', uri=True)
with conn: # col blocco with
# ci cauteliamo da errori imprevisti
cursore = conn.cursor() # otteniamo il cursore
# eseguiamo una query in linguaggio SQL al database
# notare che execute di per sè non ritorna
cursore.execute("SELECT * FROM Album LIMIT ?", [5])
for riga in cursore.fetchall(): # cursore fetchall() genera una sequenza
# di righe di risultato della query.
# in sequenza, le righe una alla volta
# vengono assegnate'oggetto `riga`
print(riga) # stampiamo la riga ottenuta
(1, 'For Those About To Rock We Salute You', 1)
(2, 'Balls to the Wall', 2)
(3, 'Restless and Wild', 2)
(4, 'Let There Be Rock', 1)
(5, 'Big Ones', 3)
Si possono anche aggiungere più punti di domanda, basta per ognuno passare il corrispondente parametro nella lista:
[6]:
import sqlite3
conn = sqlite3.connect('file:chinook.sqlite?mode=rw', uri=True)
with conn: # col blocco with ci cauteliamo da errori imprevisti
cursore = conn.cursor() # otteniamo il cursore
cursore.execute("SELECT * FROM Album WHERE AlbumId < ? AND ArtistId < ?",
[30,5])
for riga in cursore.fetchall(): # cursore fetchall() genera una sequenza
# di righe di risultato della query.
# in sequenza, le righe una alla volta
# vengono assegnate'oggetto `riga`
print(riga) # stampiamo la riga ottenuta
(1, 'For Those About To Rock We Salute You', 1)
(2, 'Balls to the Wall', 2)
(3, 'Restless and Wild', 2)
(4, 'Let There Be Rock', 1)
(5, 'Big Ones', 3)
(6, 'Jagged Little Pill', 4)
Funzione Esegui Query
Per agevolare le prossime operazioni, ci definiamo una funzione esegui che esegue le query che desideriamo e ritorna la lista delle righe ottenute:
IMPORTANTE: Fai Ctrl+Invio nella cella seguente così Python in seguito riconoscerà la funzione:
[7]:
def esegui(conn, query, params=()):
"""
Esegue una query usando la connessione conn,
e ritorna la lista di risultati ottenuti.
In params, possiamo mettere una lista di parametri
con i parametri per la nostra query.
"""
with conn:
cur = conn.cursor()
cur.execute(query, params)
return cur.fetchall()
Facciamo una prova:
[8]:
import sqlite3
conn = sqlite3.connect('file:chinook.sqlite?mode=rw', uri=True)
esegui(conn, "SELECT * FROM Album LIMIT 5")
[8]:
[(1, 'For Those About To Rock We Salute You', 1),
(2, 'Balls to the Wall', 2),
(3, 'Restless and Wild', 2),
(4, 'Let There Be Rock', 1),
(5, 'Big Ones', 3)]
Meglio ancora, per maggiore chiarezza possiamo scrivere la query usando una stringa su più linee con le triple doppie virgolette all’inizio e alla fine:
[9]:
import sqlite3
conn = sqlite3.connect('file:chinook.sqlite?mode=rw', uri=True)
esegui(conn, """
SELECT *
FROM Album
LIMIT 5
""")
[9]:
[(1, 'For Those About To Rock We Salute You', 1),
(2, 'Balls to the Wall', 2),
(3, 'Restless and Wild', 2),
(4, 'Let There Be Rock', 1),
(5, 'Big Ones', 3)]
Proviamo a passare dei parametri:
[10]:
esegui(conn, """
SELECT *
FROM Album
WHERE AlbumId < ? AND ArtistId < ?
""", [30, 5])
[10]:
[(1, 'For Those About To Rock We Salute You', 1),
(2, 'Balls to the Wall', 2),
(3, 'Restless and Wild', 2),
(4, 'Let There Be Rock', 1),
(5, 'Big Ones', 3),
(6, 'Jagged Little Pill', 4)]
ESERCIZIO: In SQLStudio, creare una query che seleziona gli album con id compreso tra 3 e 5 inclusi:
apri il query editor con
Alt+Eimmetti la query
eseguila premendo F9
ESERCIZIO: chiama esegui per eseguire la stessa query, usando i parametri
[11]:
# scrivi qui il comando
[11]:
[(3, 'Restless and Wild', 2), (4, 'Let There Be Rock', 1), (5, 'Big Ones', 3)]
Struttura della tabella
ESERCIZIO: Guarda meglio la tab Structure di Album:

DDL
Confronta quanto sopra con la tab DDL (Data Definition Language), che contiene le istruzioni SQL per creare la tabella nel database:
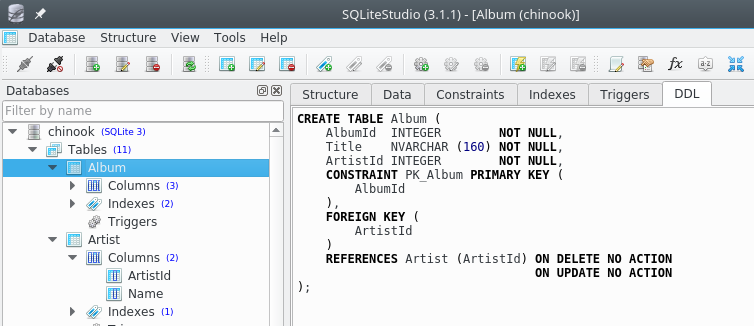
Una caratteristica dei database è la possibilità di dichiarare vincoli sui dati inseriti. Per esempio, qua notiamo che
la tabella ha una cosiddetta chiave primaria (
PRIMARY KEY): in essa asserisce che non possono esistere due righe con lo stessoAlbumIdla tabella definisce la colonna
ArtistIdcome chiave esterna (FOREIGN KEY), asserendo che ai valori in quella colonna deve sempre corrispondere un id esistente nella colonnaArtistIddella tabellaArtist. Quindi non ci si potrà mai riferire ad un artista non esistente
ESERCIZIO: Vai alla tab Data e prova a cambiare un ArtistId mettendo un numero inesistente (tipo 1000). Apparentemente il database non si lamenterà, ma solo perchè al momento non abbiamo ancora registrato il cambiamento su disco, cioè non abbiamo operato una operazione di commit. I commit ci permettono di eseguire più operazioni in modo atomico, nel senso che o tutti i cambiamenti fatti vengono registrati con successo, o non viene fatta nessuna modifica. Prova ad eseguire un commit
premendo il bottoncino verde con la spunta (o premere Ctrl-Return). Che succede? Per riparare al danno fatto, esegui rollback col bottoncino rosso con la x (o premi Ctrl-Backspace).
Query ai metadati
Una cosa interessante e a volte utile di molti database SQL è che spesso i metadati sul tipo di tabelle nel database sono salvate essi stessi come tabelle, quindi è possibile eseguire query SQL su questi metadati. Per esempio, con SQLite si può eseguire una query del genere. Non la spieghiamo nel dettaglio, limitandoci a mostrare qualche esempio di utilizzo:
[12]:
def query_schema(conn, tabella):
""" Ritorna una stringa con le istruzioni SQL per creare
la tabella (senza i dati)
"""
return esegui(conn, """
SELECT sql FROM sqlite_master
WHERE name = ?
""", (tabella,))[0][0]
[13]:
import sqlite3
conn = sqlite3.connect('file:chinook.sqlite?mode=rw', uri=True)
print(query_schema(conn, 'Album'))
CREATE TABLE [Album]
(
[AlbumId] INTEGER NOT NULL,
[Title] NVARCHAR(160) NOT NULL,
[ArtistId] INTEGER NOT NULL,
CONSTRAINT [PK_Album] PRIMARY KEY ([AlbumId]),
FOREIGN KEY ([ArtistId]) REFERENCES [Artist] ([ArtistId])
ON DELETE NO ACTION ON UPDATE NO ACTION
)
ORDER BY
Spesso vorremo ordinare il risultato in base a qualche colonna, per farlo possiamo aggiungere la clausola ORDER BY:
NOTA: se aggiungiamo LIMIT, questo viene applicato DOPO che l’ordinamento è stato fatto
[14]:
esegui(conn, """
SELECT *
FROM Album
ORDER BY Album.Title
LIMIT 10
""")
[14]:
[(156, '...And Justice For All', 50),
(257,
'20th Century Masters - The Millennium Collection: The Best of Scorpions',
179),
(296, 'A Copland Celebration, Vol. I', 230),
(94, 'A Matter of Life and Death', 90),
(95, 'A Real Dead One', 90),
(96, 'A Real Live One', 90),
(285, 'A Soprano Inspired', 219),
(139, 'A TempestadeTempestade Ou O Livro Dos Dias', 99),
(203, 'A-Sides', 132),
(160, 'Ace Of Spades', 106)]
Per ordinare in ordine decrescente possiamo aggiungere DESC:
[15]:
esegui(conn, """
SELECT *
FROM Album
ORDER BY Album.Title DESC
LIMIT 10
""")
[15]:
[(208, '[1997] Black Light Syndrome', 136),
(240, 'Zooropa', 150),
(267, 'Worlds', 202),
(334, 'Weill: The Seven Deadly Sins', 264),
(8, 'Warner 25 Anos', 6),
(239, 'War', 150),
(175, 'Walking Into Clarksdale', 115),
(287, 'Wagner: Favourite Overtures', 221),
(182, 'Vs.', 118),
(53, 'Vozes do MPB', 21)]
JOIN
Nella tabella Album per gli artisti vediamo solo dei numeri. Come possiamo fare una query per vedere anche i nomi degli artisti? Useremo il comando SQL JOIN :
ESERCIZIO: Per capire cosa succede, esegui le query in SQLStudio
[16]:
esegui(conn, """
SELECT *
FROM Album JOIN Artist
WHERE Album.ArtistId = Artist.ArtistId
LIMIT 5
""")
[16]:
[(1, 'For Those About To Rock We Salute You', 1, 1, 'AC/DC'),
(2, 'Balls to the Wall', 2, 2, 'Accept'),
(3, 'Restless and Wild', 2, 2, 'Accept'),
(4, 'Let There Be Rock', 1, 1, 'AC/DC'),
(5, 'Big Ones', 3, 3, 'Aerosmith')]
Invece del JOIN possiamo usare una virgola:
[17]:
esegui(conn, """
SELECT * FROM Album, Artist
WHERE Album.ArtistId = Artist.ArtistId
LIMIT 5
""")
[17]:
[(1, 'For Those About To Rock We Salute You', 1, 1, 'AC/DC'),
(2, 'Balls to the Wall', 2, 2, 'Accept'),
(3, 'Restless and Wild', 2, 2, 'Accept'),
(4, 'Let There Be Rock', 1, 1, 'AC/DC'),
(5, 'Big Ones', 3, 3, 'Aerosmith')]
Meglio ancora, in questo caso visto che abbiamo lo stesso nome di colonna in entrambe le tabelle, possiamo usare la clausola USING che ha anche il beneficio di eliminare la colonna duplicata
NOTA: Per ragioni oscure, in SQLiteStudio la colonna ArtistId appare comunque duplicata con nome ArtistiId:1
[18]:
esegui(conn, """
SELECT *
FROM Album, Artist USING(ArtistId)
LIMIT 5
""")
[18]:
[(1, 'For Those About To Rock We Salute You', 1, 'AC/DC'),
(2, 'Balls to the Wall', 2, 'Accept'),
(3, 'Restless and Wild', 2, 'Accept'),
(4, 'Let There Be Rock', 1, 'AC/DC'),
(5, 'Big Ones', 3, 'Aerosmith')]
Infine possiamo selezionare solo le colonne che ci interessano, Title di album e Name di Artisti. Per chiarezza, possiamo identificare le tabelle con variabili che assegnamo in FROM (qua usiamo i nomi ALB e ART ma potrebbero essere qualsiasi):
[19]:
esegui(conn, """
SELECT ALB.Title, ART.Name
FROM Album ALB, Artist ART USING(ArtistId)
LIMIT 5
""")
[19]:
[('For Those About To Rock We Salute You', 'AC/DC'),
('Balls to the Wall', 'Accept'),
('Restless and Wild', 'Accept'),
('Let There Be Rock', 'AC/DC'),
('Big Ones', 'Aerosmith')]
Tabella Track
Passiamo adesso ad una tabella più complessa, come Track, che contiene canzoni ascoltate dagli utenti di iTunes:
[20]:
esegui(conn, "SELECT * FROM Track LIMIT 5")
[20]:
[(1,
'For Those About To Rock (We Salute You)',
1,
1,
1,
'Angus Young, Malcolm Young, Brian Johnson',
343719,
11170334,
0.99),
(2, 'Balls to the Wall', 2, 2, 1, None, 342562, 5510424, 0.99),
(3,
'Fast As a Shark',
3,
2,
1,
'F. Baltes, S. Kaufman, U. Dirkscneider & W. Hoffman',
230619,
3990994,
0.99),
(4,
'Restless and Wild',
3,
2,
1,
'F. Baltes, R.A. Smith-Diesel, S. Kaufman, U. Dirkscneider & W. Hoffman',
252051,
4331779,
0.99),
(5,
'Princess of the Dawn',
3,
2,
1,
'Deaffy & R.A. Smith-Diesel',
375418,
6290521,
0.99)]
[21]:
query_schema(conn, "Track")
[21]:
'CREATE TABLE [Track]\n(\n [TrackId] INTEGER NOT NULL,\n [Name] NVARCHAR(200) NOT NULL,\n [AlbumId] INTEGER,\n [MediaTypeId] INTEGER NOT NULL,\n [GenreId] INTEGER,\n [Composer] NVARCHAR(220),\n [Milliseconds] INTEGER NOT NULL,\n [Bytes] INTEGER,\n [UnitPrice] NUMERIC(10,2) NOT NULL,\n CONSTRAINT [PK_Track] PRIMARY KEY ([TrackId]),\n FOREIGN KEY ([AlbumId]) REFERENCES [Album] ([AlbumId]) \n\t\tON DELETE NO ACTION ON UPDATE NO ACTION,\n FOREIGN KEY ([GenreId]) REFERENCES [Genre] ([GenreId]) \n\t\tON DELETE NO ACTION ON UPDATE NO ACTION,\n FOREIGN KEY ([MediaTypeId]) REFERENCES [MediaType] ([MediaTypeId]) \n\t\tON DELETE NO ACTION ON UPDATE NO ACTION\n)'
[22]:
print(query_schema(conn, "Track"))
CREATE TABLE [Track]
(
[TrackId] INTEGER NOT NULL,
[Name] NVARCHAR(200) NOT NULL,
[AlbumId] INTEGER,
[MediaTypeId] INTEGER NOT NULL,
[GenreId] INTEGER,
[Composer] NVARCHAR(220),
[Milliseconds] INTEGER NOT NULL,
[Bytes] INTEGER,
[UnitPrice] NUMERIC(10,2) NOT NULL,
CONSTRAINT [PK_Track] PRIMARY KEY ([TrackId]),
FOREIGN KEY ([AlbumId]) REFERENCES [Album] ([AlbumId])
ON DELETE NO ACTION ON UPDATE NO ACTION,
FOREIGN KEY ([GenreId]) REFERENCES [Genre] ([GenreId])
ON DELETE NO ACTION ON UPDATE NO ACTION,
FOREIGN KEY ([MediaTypeId]) REFERENCES [MediaType] ([MediaTypeId])
ON DELETE NO ACTION ON UPDATE NO ACTION
)
[23]:
esegui(conn, """
SELECT Name, Composer
FROM Track
LIMIT 5
""")
[23]:
[('For Those About To Rock (We Salute You)',
'Angus Young, Malcolm Young, Brian Johnson'),
('Balls to the Wall', None),
('Fast As a Shark', 'F. Baltes, S. Kaufman, U. Dirkscneider & W. Hoffman'),
('Restless and Wild',
'F. Baltes, R.A. Smith-Diesel, S. Kaufman, U. Dirkscneider & W. Hoffman'),
('Princess of the Dawn', 'Deaffy & R.A. Smith-Diesel')]
[24]:
esegui(conn, """
SELECT Name, Composer
FROM Track
LIMIT 5
""")[0]
[24]:
('For Those About To Rock (We Salute You)',
'Angus Young, Malcolm Young, Brian Johnson')
Per la seconda riga:
[25]:
esegui(conn, """
SELECT Name, Composer
FROM Track
LIMIT 5
""")[1]
[25]:
('Balls to the Wall', None)
Notiamo che in questo caso manca il compositore. Ma sorge una domanda: nella tabella originale SQL, come era segnato il fatto che il compositore mancasse?
ESERCIZIO: Usando SQLiteStudio, nel menu a sinistra fai doppio click sulla tabella Track e poi seleziona la tab Data a destra. Scorri le righe finchè non trovi la casella per la colonna Composer.
Proviamo a selezionare dei valori numerici alla nostra query, come per esempio i Milliseconds
[26]:
esegui(conn, """
SELECT Name, Milliseconds
FROM Track
LIMIT 5
""")
[26]:
[('For Those About To Rock (We Salute You)', 343719),
('Balls to the Wall', 342562),
('Fast As a Shark', 230619),
('Restless and Wild', 252051),
('Princess of the Dawn', 375418)]
[27]:
esegui(conn, """
SELECT Name, Milliseconds
FROM Track
LIMIT 5
""")[0]
[27]:
('For Those About To Rock (We Salute You)', 343719)
[28]:
esegui(conn, """
SELECT Name, Milliseconds
FROM Track
LIMIT 5
""")[0][0]
[28]:
'For Those About To Rock (We Salute You)'
[29]:
esegui(conn, """
SELECT Name, Milliseconds
FROM Track
LIMIT 5
""")[0][1]
[29]:
343719
[30]:
esegui(conn, """
SELECT Name, Milliseconds
FROM Track
ORDER BY Milliseconds DESC
LIMIT 5
""")
[30]:
[('Occupation / Precipice', 5286953),
('Through a Looking Glass', 5088838),
('Greetings from Earth, Pt. 1', 2960293),
('The Man With Nine Lives', 2956998),
('Battlestar Galactica, Pt. 2', 2956081)]
ESERCIZIO: Prova ad usare ASC invece di DESC
[31]:
# scrivi qui la query
[31]:
[('É Uma Partida De Futebol', 'Samuel Rosa', 1071),
('Now Sports', None, 4884),
('A Statistic', None, 6373),
('Oprah', None, 6635),
('Commercial 1', 'L. Muggerud', 7941)]
Aggregare i dati
COUNT
Per contare quante righe ci sono in una tabella, possiamo usare la parola chiave COUNT(*) nella SELECT. Per esempio, per vedere quante tracce ci sono, possiamo fare così:
[32]:
esegui(conn, """
SELECT COUNT(*)
FROM Track
""")
[32]:
[(3503,)]
DOMANDA: è molto meglio fare così, invece che prelevare tutte le righe in Python e contare con len. Perchè?
GROUP BY e COUNT
Ogni Track ha associato un MediaTypeId. Potremmo chiederci per ogni media type quante track ci sono.
Per conteggiare, dovremo usare la parola chiave
COUNT(*) AS ConteggionellaSELECTper raggruppare
GROUP BYdopo la linea delFROMPer ordinare i conteggi in modo decrescente, useremo anche
ORDER BY Conteggio DESC
Nota: il COUNT(*) conteggierà in questo caso quanti elementi ci sono nei gruppi, non in tutta la tabella:
[33]:
esegui(conn, """
SELECT T.MediaTypeId, COUNT(*) AS Conteggio
FROM Track T
GROUP BY T.MediaTypeId
ORDER BY Conteggio DESC
""")
[33]:
[(1, 3034), (2, 237), (3, 214), (5, 11), (4, 7)]
ESERCIZIO: I MediaTypeId non sono molto descrittivi. Scrivi qua sotto una query per ottenere coppie con nome del MediaType e rispettivo conteggio. Prova anche ad eseguire la query in SQLStudio:
[34]:
# scrivi qui
[34]:
[('MPEG audio file', 3034),
('Protected AAC audio file', 237),
('Protected MPEG-4 video file', 214),
('AAC audio file', 11),
('Purchased AAC audio file', 7)]
ESERCIZIO: Scrivi qua sotto una query per creare una tabella di due colonne, nella prima ci saranno i nomi dei generi musicali e nella seconda quante track di quel genere ci sono nel database.
Mostra soluzione[35]:
# scrivi qui
[35]:
[('Rock', 1297),
('Latin', 579),
('Metal', 374),
('Alternative & Punk', 332),
('Jazz', 130),
('TV Shows', 93),
('Blues', 81),
('Classical', 74),
('Drama', 64),
('R&B/Soul', 61),
('Reggae', 58),
('Pop', 48),
('Soundtrack', 43),
('Alternative', 40),
('Hip Hop/Rap', 35),
('Electronica/Dance', 30),
('Heavy Metal', 28),
('World', 28),
('Sci Fi & Fantasy', 26),
('Easy Listening', 24),
('Comedy', 17),
('Bossa Nova', 15),
('Science Fiction', 13),
('Rock And Roll', 12),
('Opera', 1)]
ESERCIZIO: Ora prova a trovare per ogni genere la lunghezza media in millisecondi usando invece di COUNT(*) la funzione AVG(Track.Milliseconds):
[36]:
# scrivi qui:
[36]:
[('Sci Fi & Fantasy', 2911783.0384615385),
('Science Fiction', 2625549.076923077),
('Drama', 2575283.78125),
('TV Shows', 2145041.0215053763),
('Comedy', 1585263.705882353),
('Metal', 309749.4438502674),
('Electronica/Dance', 302985.8),
('Heavy Metal', 297452.9285714286),
('Classical', 293867.5675675676),
('Jazz', 291755.3769230769),
('Rock', 283910.0431765613),
('Blues', 270359.77777777775),
('Alternative', 264058.525),
('Reggae', 247177.75862068965),
('Soundtrack', 244370.88372093023),
('Alternative & Punk', 234353.84939759035),
('Latin', 232859.26252158894),
('Pop', 229034.10416666666),
('World', 224923.82142857142),
('R&B/Soul', 220066.8524590164),
('Bossa Nova', 219590.0),
('Easy Listening', 189164.20833333334),
('Hip Hop/Rap', 178176.2857142857),
('Opera', 174813.0),
('Rock And Roll', 134643.5)]
Pandas
Finora abbiamo usato metodi base di Python, ma ovviamente processare il tutto in pandas è più comodo.
Per maggiori informazioni su Pandas, guarda il relativo tutorial
[37]:
import pandas
df = pandas.read_sql_query("SELECT Name, Composer, Milliseconds from Track", conn)
[38]:
df
[38]:
| Name | Composer | Milliseconds | |
|---|---|---|---|
| 0 | For Those About To Rock (We Salute You) | Angus Young, Malcolm Young, Brian Johnson | 343719 |
| 1 | Balls to the Wall | None | 342562 |
| 2 | Fast As a Shark | F. Baltes, S. Kaufman, U. Dirkscneider & W. Ho... | 230619 |
| 3 | Restless and Wild | F. Baltes, R.A. Smith-Diesel, S. Kaufman, U. D... | 252051 |
| 4 | Princess of the Dawn | Deaffy & R.A. Smith-Diesel | 375418 |
| ... | ... | ... | ... |
| 3498 | Pini Di Roma (Pinien Von Rom) \ I Pini Della V... | None | 286741 |
| 3499 | String Quartet No. 12 in C Minor, D. 703 "Quar... | Franz Schubert | 139200 |
| 3500 | L'orfeo, Act 3, Sinfonia (Orchestra) | Claudio Monteverdi | 66639 |
| 3501 | Quintet for Horn, Violin, 2 Violas, and Cello ... | Wolfgang Amadeus Mozart | 221331 |
| 3502 | Koyaanisqatsi | Philip Glass | 206005 |
3503 rows × 3 columns
ATTENZIONE a quanti dati carichi !
Pandas è molto comodo, ma come già detto nella nel relativo tutorial Pandas carica tutto in memoria RAM che tipicamente sono dai 4 ai 16 giga. Se hai grandi database potresti avere dei problemi per cui valgono i metodi e considerazioni fatte nella sezione Performance
ESERCIZIO: Millisecondi e bytes occupati dovrebbero ragionevolmente essere linearmente dipendenti. Dimostralo con Pandas.
Mostra soluzione[39]:
# scrivi qui